Qwen2-Math,新一代数学模型
GITHUB HUGGING FACE MODELSCOPEDISCORD
此模型目前主要支持英语。我们将尽快推出中英双语版本。
简介
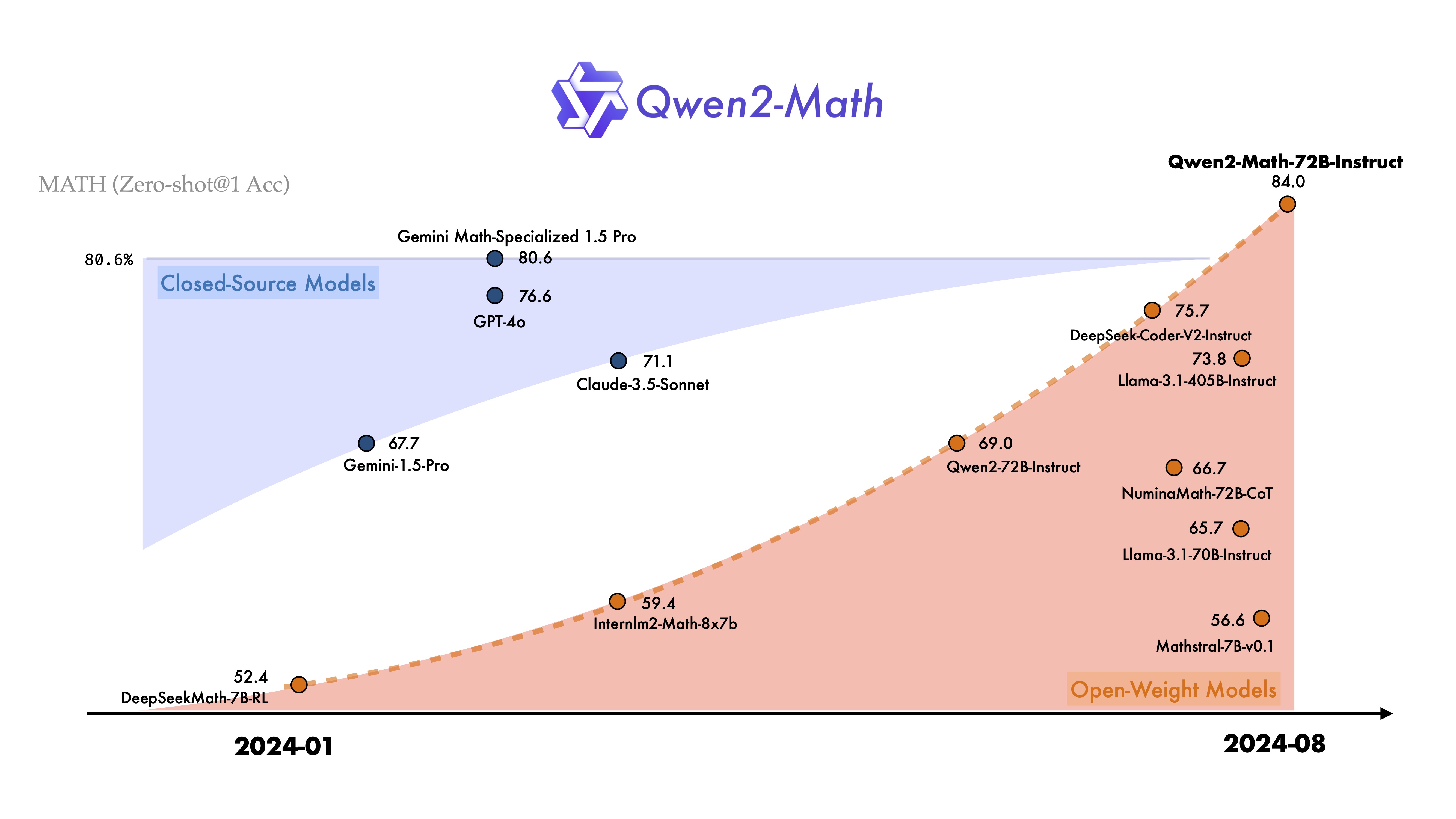
在过去的一年里,我们非常关注大模型的推理能力的提升,尤其关注其在数学相关的任务上的表现。今天,我们非常高兴地介绍 Qwen2 开源家族的新成员——Qwen2-Math-1.5B/7B/72B 系列。Qwen2-Math 是一系列基于 Qwen2 LLM 构建的专门用于数学解题的语言模型,其数学能力显著超越了开源模型,甚至超过了闭源模型(如 GPT-4o)。我们希望Qwen2-Math能够为科学界解决需要复杂多步逻辑推理的高级数学问题做出贡献。
我们在一系列数学基准评测上评估了我们的数学专用模型 Qwen2-Math。在 Math 上的评测结果表明,我们最大的数学专用模型 Qwen2-Math-72B-Instruct 超越了最先进的模型,包括 GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro 和 Llama-3.1-405B。
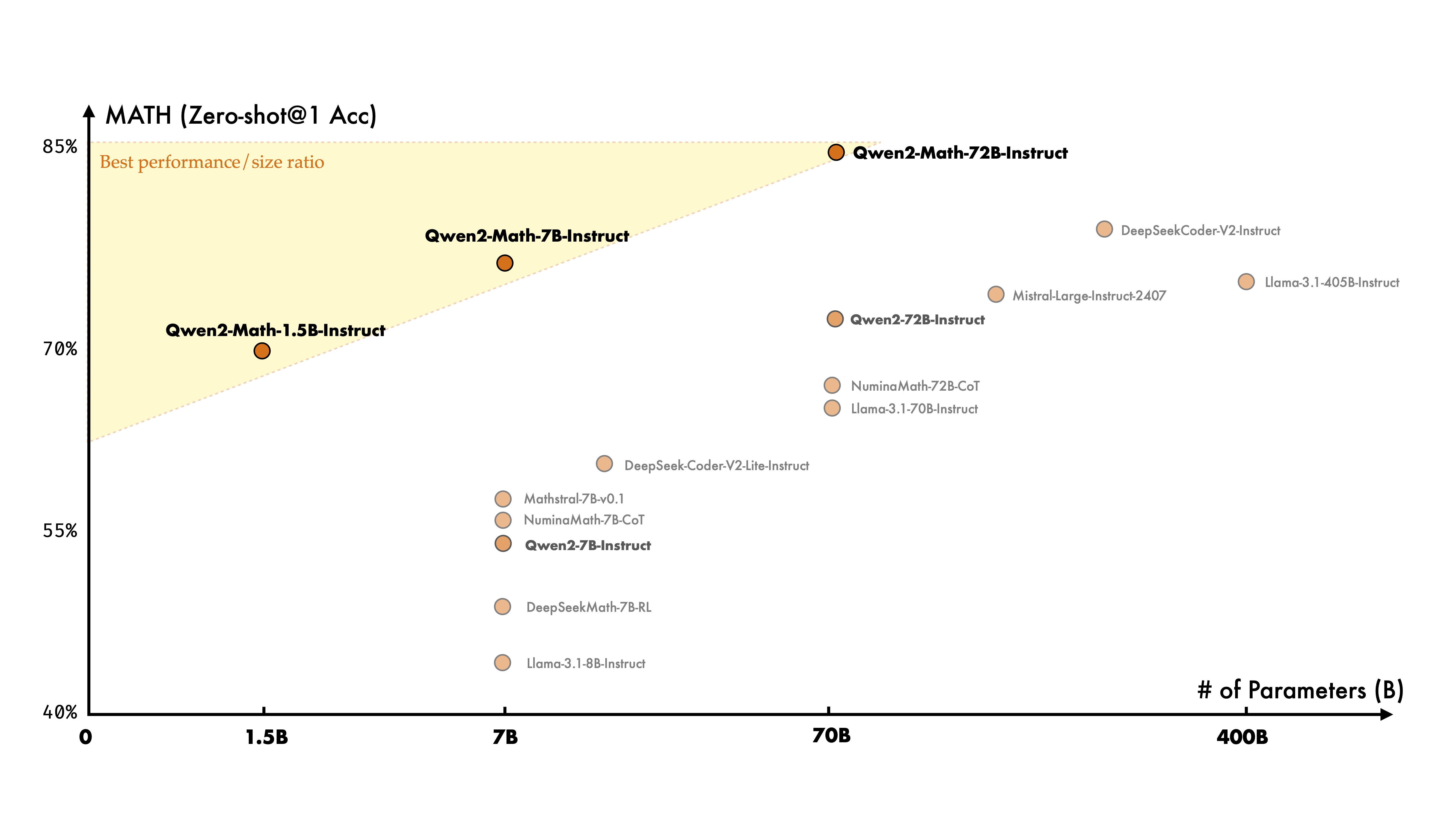
Qwen2-Math基础模型
Qwen2-Math 的基础模型使用 Qwen2-1.5B/7B/72B 进行初始化,然后在精心设计的数学专用语料库上进行预训练,该语料库包含大规模高质量的数学网络文本、书籍、代码、考试题目以及由 Qwen2 模型合成的数学预训练数据。
我们在三个广泛使用的英语数学基准 GSM8K、Math 和 MMLU-STEM 上评估了我们的 Qwen2-Math 基模型。此外,我们还评估了三个中国数学基准 CMATH,GaoKao Math Cloze 和 GaoKao Math QA。所有评估均使用 Few-shot CoT 方式。

Qwen2-Math指令微调模型
我们首先基于 Qwen2-Math-72B 训练了一个数学专用的奖励模型。然后,我们将这个密集的奖励信号与一个二元信号结合,该二元信号指示模型是否正确回答了问题。这个组合信号被用作监督来通过拒绝采样构建 SFT 数据,并在此SFT模型的基础上进一步使用 GRPO 来优化模型。
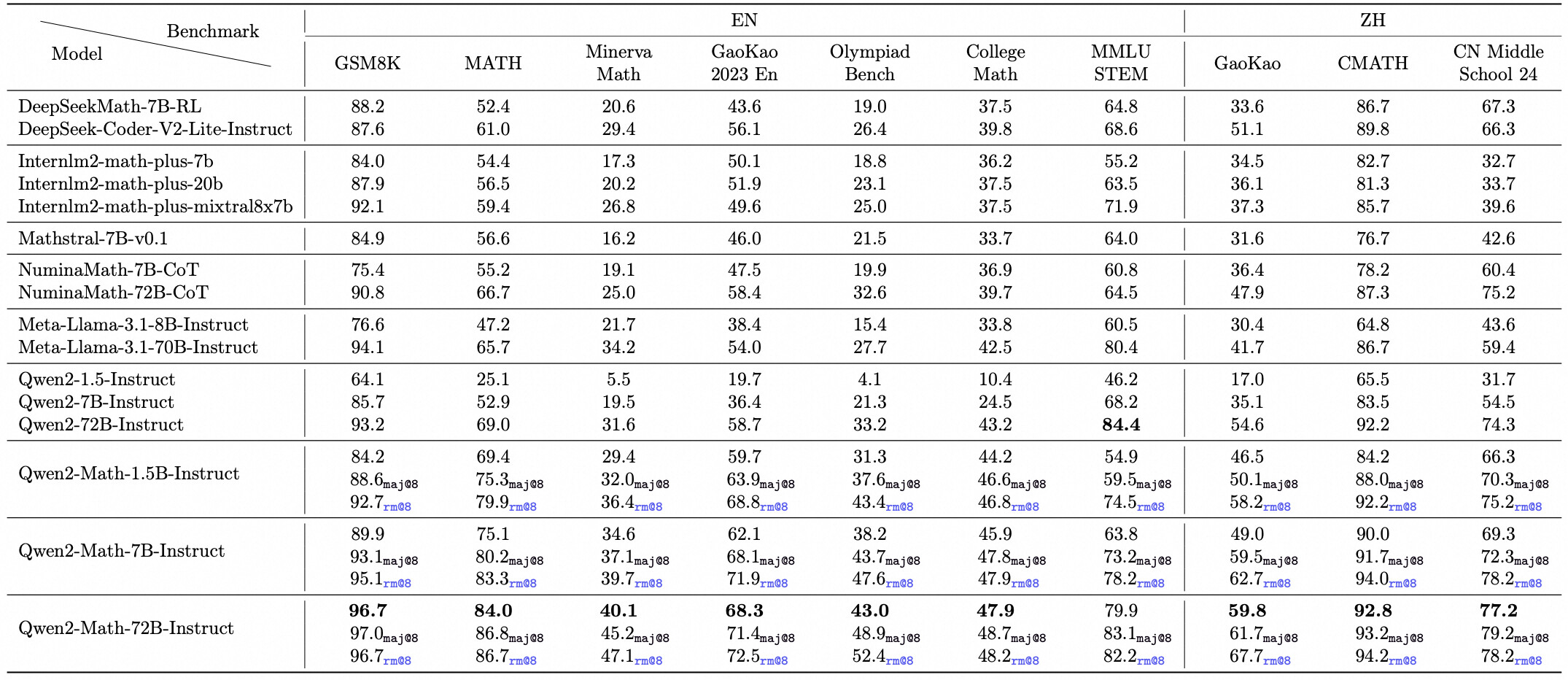
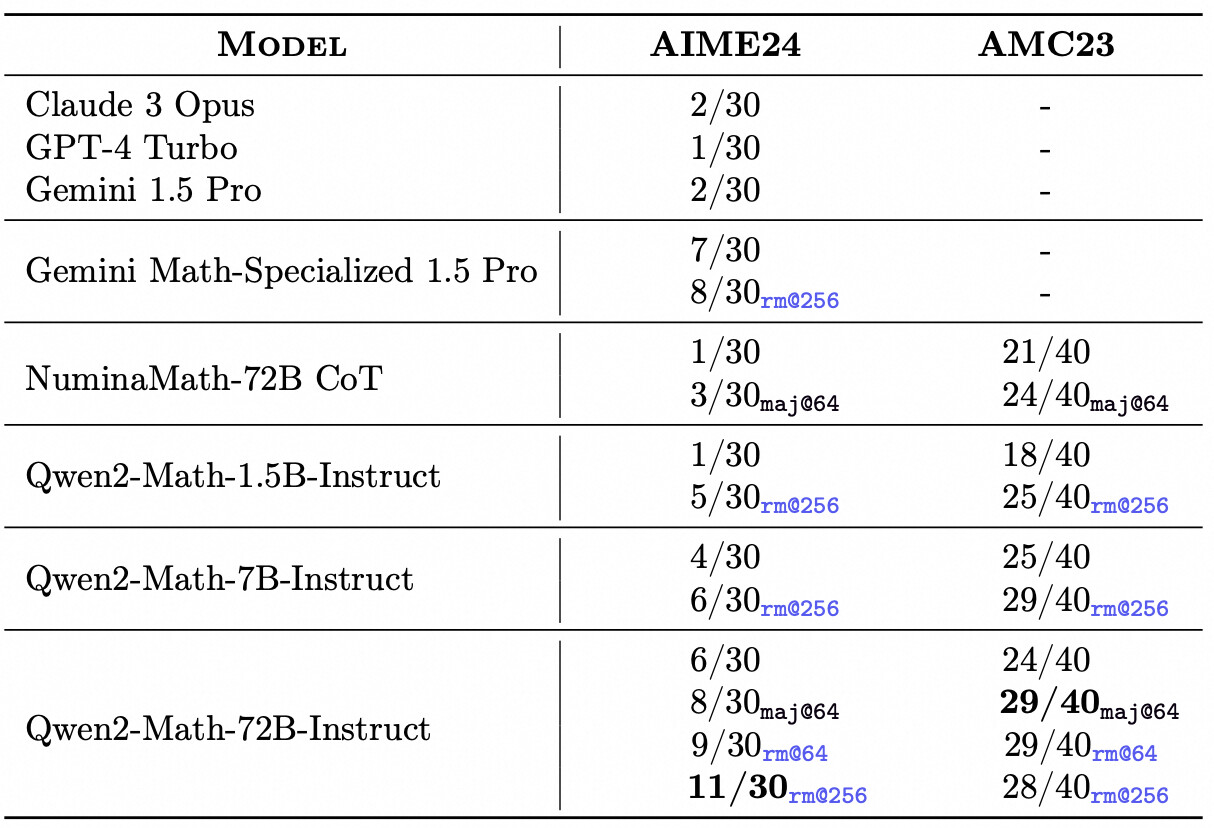
我们对 Qwen2-Math-Instruct 在英语和中文的数学基准评测上进行了评估。除了常用的基准评测,如 GSM8K 和 MATH 之外,我们还加入了更具挑战性的考试以全面检测 Qwen2-Math-Instruct 的能力,例如 OlympiadBench、CollegeMath、高考(GaoKao)、AIME2024 以及 AMC2023。对于中文的数学评测集,我们使用了 CMATH、2024年中国高考数学题以及2024年中国中考数学题。
我们汇报了在 greedy 和 RM@8 的条件下模型在各个基准评测上的 0-shot 成绩,对于选择题类型的题目,如 MMLU(STEM),我们使用了 5-shot 进行评测。
案例分析
这里我们列举了一些测试的竞赛题,其中包括了多道 IMO 竞赛题。通过评测及具体样例分析,我们发现 Qwen2-Math 已经具备了解决一些简单竞赛题的数学能力。欢迎点击下方折叠块查看样例!
Problem From IMO Shortlist 2002Problem From IMO Shortlist 2022Problem From IMO 2022Problem from International Zhautykov Olympiad 2020Problem From Baltic Way 2023Problem From Lusophon Mathematical Olympiad 2023Problem From Balkan MO 2023Problem From Math OdysseyProblem from USAMO 2010Problem from JBMO Shortlist 2011
去除数据污染
我们在预训练和微调数据集上都进行了去污染处理。具体来说,对于预训练数据,我们针对数学数据集,包括 GSM8K、MATH,并移除与测试集有显著重叠的样本。我们移除了有13-gram重复且最长公共子序列比例大于0.6的训练样本。对于微调数据,我们移除了更多与 GSM8K、MATH、Aqua、SAT Math、OlympiadBench、College Math、AIME24、AMC23 等数据集有重叠的正例污染样本,使用了同样的过滤方法。
总结
这次我们发布的新模型系列 Qwen2-Math 专注于数学能力,构建于Qwen2的基础之上。我们的旗舰模型 Qwen2-Math-72B-Instruct 在数学相关任务上超越了诸如 GPT-4o 和 Claude 3.5 等专有模型。鉴于目前仅支持英文的限制,我们计划很快推出支持英文和中文的双语模型,并且多语言模型也在开发之中。此外,我们将持续增强模型解决复杂及具有挑战性的数学问题的能力。
Last edited by @suen 2024-08-08T23:57:29Z